Working with large keyspaces
By default, RESP.app uses * (wildcard glob-style pattern) in SCAN command to load all keys from the selected database. It’s simple and user-friendly for cases when you have only a couple of thousands keys. But for production redis-servers with millions of keys it leads to a huge amount of time needed to load keys in RESP.app.
On this page you will find different approaches how to work with large Redis keyspaces efficiently.
Increase limit for SCAN command
RESP.app limits amount of keys that should be scanned by Redis to 10000. If you have more than 100K keys in Redis it's recommended to increase this limit to
50000 or 100000.
Be careful!
High scanning limit may affect your Redis performance!
To increase this limit click on the Settings button in top right corner for the main window and change value for Limit for SCAN command setting.
Use specific SCAN filter to reduce loaded amount of keys
Consider using more specific filters for SCAN in order to speed up keys loading and reduce memory footprint
- Right click on database and click on Filter button

- Enter glob-style pattern and press apply button

Note
More details about
SCANfilter syntax you can find in Redis documentation https://redis.io/commands/scan#the-match-option
Default SCAN filter can be changed in connection settings on “Advanced Settings” tab:

Use namespaced keys
Colon sign : is a commonly used convention when naming Redis keys. For example you can use following schema to store information about users:
user:1000
Following this schema allows you to simplify removal of obsolete keys and performing other operations with keys in Redis.
Using namespaced keys is also important for loading huge keyspaces in RESP.app. It renders namespaces on demand (since 2020.2+) and this approach allows to visualise millions of keys with small memory footprint.
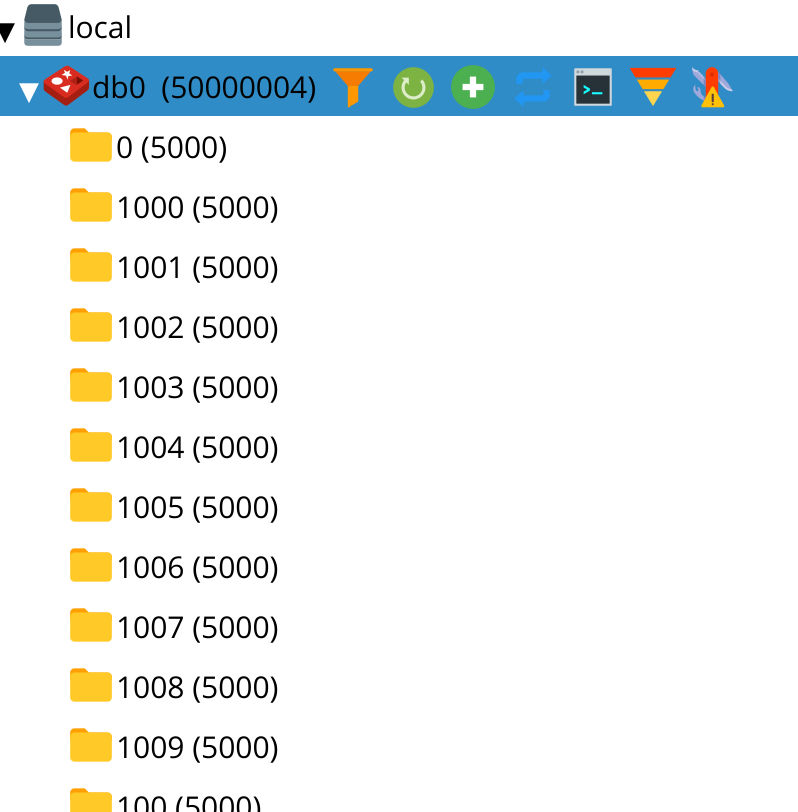
Default namespace separator can be changed in connection settings on “Advanced Settings” tab.
More tips about Redis keys naming you can find in this tutorial https://redis.io/topics/data-types-intro#redis-keys